
전염병 예측 인공지능 만들기
블루닷이라는 서비스는 코로나 19의 확산을 누구보다 먼저 예측한 인공지능으로 유명
인공지능을 사용하여 전염병ㅇ이 발생할 수 있는 곳을 예측하는 기술이 이미 사용되고 있다
인공지능을 사용하여 전염병의 발병률을 예측하기도 한다
이번에 만드는 인공지능은 이전 3일의 확진자 수를 토대로 다음 날의 확진자 수를 예측하는 간단한 인공지능
확진자 수 예측하는 인공지능
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import math
import numpy as np
import matplotlib.pyplot as plt
from pandas import read_csv
sklearn 라이브러리의 전처리 함수
- MinMaxScaler 함수는 데이터를 정규화 할때 사용
- mean_squared_error 함수는 제 값과 예측 값의 차이를 사용하여 오류를 구하는 역할
- train_test_split 함수는 데이터를 훈련 데이터와 검증 데이터로 나누는 명령어
수학 계산을 도와주는 math 라이브러리
수학 계산 라이브러리인 numpy
그래프 라이브러리인 matplotlib 의 pyplot 라이브러리를 사용
csv 파일을 불러올 수 있는 read_csv 함수를 pandas 라이브러리에서 불러옴
데이터 가져오기
!git clone https://github.com/yhlee1627/deeplearning.git
dataframe = read_csv('/content/deeplearning/corona_daily.csv', usecols=[3], engine='python', skipfooter=3)
print(dataframe)
dataset = dataframe.values
dataset = dataset.astype('float32')
데이터 정규화 및 분류
인공지능 모델의 성능을 높이려면 데이터 정규화가 필요함
scaler = MinMaxScaler(feature_range=(0, 1))
Dataset = scaler.fit_transform(dataset)
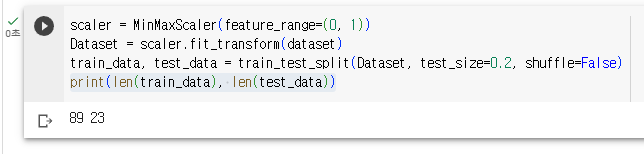
train_data, test_data = train_test_split(Dataset, test_size=0.2, shuffle=False)
print(len(train_data), len(test_data))
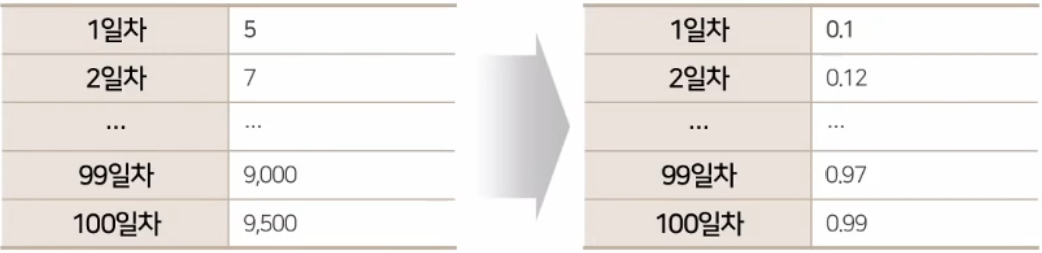
scaler = MinMaxScaler(feature_range=(0, 1))정규화하기 위한 방법으로 scaler로 정하고 이를 위해 사이킷런 라이브러리 중 MinMaxScaler 함수를 사용
데이터를 정규화하는 범위를 0~1 사이의 값으로 정한다

train_data, test_data = train_test_split(Dataset, test_size=0.2, shuffle=False)train_test_split 함수를 사용하여 전체 데이터를 훈련 데이터와 검증 데이터로 분류
분류할 데이터(Dataset)
검증 데이터 비율(test_size=0.2)
추출하는 방법(shuffle=False)
추출하는 방법(shuffle)
첫 번째는 무작위 추출(shuffle=True)
두 번째는 순차 추출(shuffle=False)
print(len(train_data), len(test_data))훈련 데이터의 개수와 검증 데이터의 개수를 출력
데이터 형태 변경
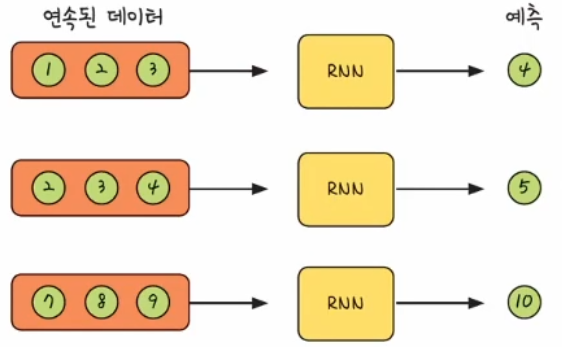
- 순환 신경망(RNN) 모델은 이전의 연속된 데이터를 사용하여 이후의 값을 예측한다
- 1, 2, 3일차의 확진자 수를 순환 신경망 모델에 넣으면 그다음 날짜의 확진자 수를 예측해서 반환한다
- 그리고 7, 8, 9일차의 확진자 수를 순환 신경망 모델에 넣으면 그다음 날짜의 확진자 수를 예측해서 반환한다
- 그런데 이러한 형태의 예측을 위해서는 데이터의 모습 또한 이에 맞게끔 변경한다
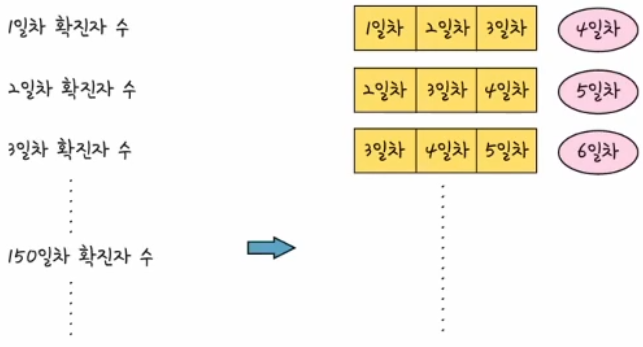
- 이와 같이 한 줄로 나열된 데이터를 연속된 데이터의 형태로 바꾸어 주는 과정이 필요

def create_dataset(dataset, look_back):
x_data = []
y_data = []
for i in range(len(dataset)-look_back-1):
data = dataset[i:(i+look_back), 0]
x_data.append(data)
y_data.append(dataset[i + look_back, 0])
return np.array(x_data), np.array(y_data)
data = dataset[i:(i+look_back), 0]- 첫 번째 반복에서의 i는 0
- 머전 1일차부터 3일차까지의 데이터를 뽑아야 하기 때문에 전체 데이터의 첫 번째부터 세 번째까지 열의 데이터를 추출한다. dataset[0:3,0]
- 이렇게 데이터를 추출할 때 확진자 수를 나타내는 첫 번쨰 열에서만 추출하기 때문에 숫자 0을 입력
- 두 번째 반복에서의 i는 1
- 2일차부터 4일차까지의 데이터를 뽑아야 하므로 dataset[1:4,0] 과 같이 된다.
입력 데이터 생성
look_back = 3
x_train, y_train = create_dataset(train_data, look_back)
x_test, y_test = create_dataset(test_data, look_back)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)


인공지능 모델에 넣어줄 형태로 변환
우리가 지금 가진 데이터의 모습은 3개의 데이터가 85층으로 이루어진 모습이다
이 데이터를 1*3의 형태로 85개를 넣어야 한다.

X_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1]))
X_test = np.reshape(x_test, (x_test.shape[0], 1, x_test.shape[1]))
print(X_train.shape)
print(X_test.shape)
인공지능 모델 만들기
model = Sequential()
model.add(SimpleRNN(3, input_shape=(1, look_back)))
model.add(Dense(1, activation="linear"))
model.compile(loss='mse', optimizer='adam')
model.summary()
model.add(SimpleRNN(3, input_shape=(1, look_back)))RNN 기법 중 SimpleRNN 사용
SimpleRNN의 뉴련의 수는 3개이며, 어떤 데이터의 형태를 넣는지 결정해준다.
데이터의 형태는 몇 개의 연속된 데이터를 넣을지에 따라 달라지기 때문에 (1, look_back)의 형태로 설정

이처럼 한 번에 1*3 형태인 3일치 데이터를 넣기 때문에 (1, look_back)을 넣는다
model.compile(loss='mse', optimizer='adam')손실 함수는 mse(평균 제곱 오차, mean_squared_error)

모델 학습
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1)
데이터 예측
모델의 성능을 측정하려면 실제 데이터를 예측한 값과 실제 데이터의 값의 차이를 봐야 함
그러므로 정규화를 거친 결과가 아닌 실제 확진자 수 데이터가 필요
RNN 모델을 통해 나온 예측 값을 정규화되지 전의 값으로 변환하여야 하며 실제 값 또는 정규화되기전의 값으로 변환
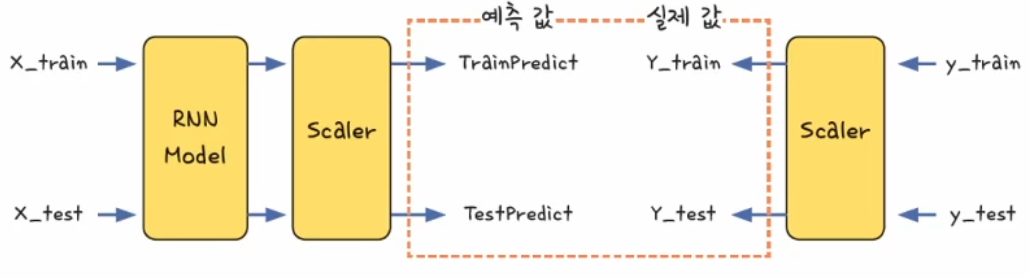
trainPredict = model.predict(X_train)
testPredict = model.predict(X_test)
TrainPredict = scaler.inverse_transform(trainPredict)
Y_train = scaler.inverse_transform([y_train])
TestPredict = scaler.inverse_transform(testPredict)
Y_test = scaler.inverse_transform([y_test])
모델의 정확도
trainScore = math.sqrt(mean_squared_error(Y_train[0], TrainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(Y_test[0], TestPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))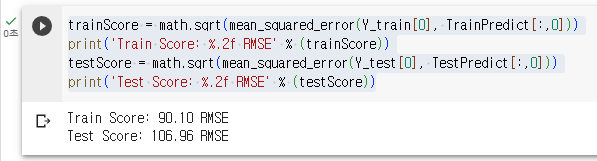
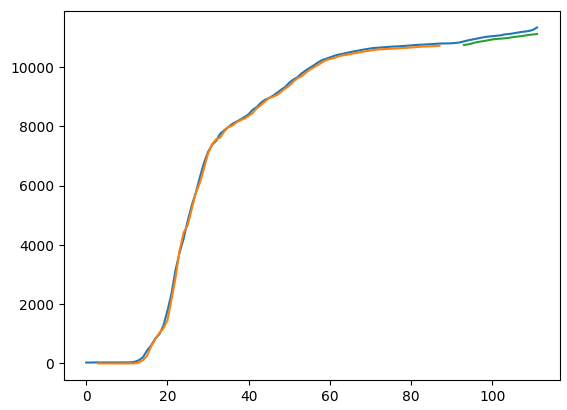
결과를 그래프로 확인
- 앞에서 평균 제곱근 오차(RMSE)를 구하여 모델의 정확도를 살펴보았지만, 이 점수만으로 모델이 어느정도 정확한지 한눈에 파악하기 쉽지않다
- 그렇기 때문에 실제 데이터의 그래프와 훈련데이터를 예측한 그래프, 검증 데이터를 예측한 그래프를 한 번에 그려서 비교해 봄
- 주황색과 초록색 선이 인공지능이 예측한 확진자 수
파란색 선이 실제 확진자 수 - 그래프를 보면 인공지능이 실제와 유사한 흐름으로 예측한 것을 확인할 수 있다
- 직전 3일치를 바탕으로 다음 날을 예측하기 때문에 처음 3일 동안의 예측 값이 없는 것을 볼 수 있다.

trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(TrainPredict)+look_back, :] = TrainPredict
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(TrainPredict)+(look_back+1)*2:len(dataset), :] = TestPredict
plt.plot(dataset)
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
숫자 생성 인공지능 만들기
GAN(Generative adversarial network) - 적대적 생성 신경망
생성자와 판별자는 서로를 이기기 위해 학습
그러면 생성자는 판별자가 진짜와 가짜를 구별하지 못할 정도로 진짜 같은 그림을 만들어 낸다
이헐게 두 개의 신경망을 사용하여 새로운 그림을 생성해 내는 기법이 바로 적대적 생성 신경망(GAN)

from keras.models import Model, Sequential
from keras.layers import Dense, Input
from keras.optimizers import Adam
from keras.datasets import mnist
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as plt
데이터 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_test = (x_test.astype(np.float32) - 127.5)/127.5
mnist_data = x_test.reshape(10000, 784)
print(mnist_data.shape)
len(mnist_data)
본 후기는 정보통신산업진흥원(NIPA)에서 주관하는 <AI 서비스완성! AI+웹개발 취업캠프 - 프론트엔드&백엔드> 과정 학습/프로젝트/과제 기록으로 작성되었습니다.
'코딩캠프 > AI 웹개발 취업캠프' 카테고리의 다른 글
| [AI 웹개발 취업캠프] 61Day - 프로젝트 12일차 (0) | 2023.10.17 |
|---|---|
| [AI 웹개발 취업캠프] 60Day - 프로젝트 11일차 (0) | 2023.10.16 |
| [AI 웹개발 취업캠프] 33Day - 숫자 구분 인공지능(예비군/4일차) (0) | 2023.08.31 |
| [AI 웹개발 취업캠프] 32Day - 파이썬과 코랩(예비군/3일차) (0) | 2023.08.30 |
| [AI 웹개발 취업캠프] 31Day - 딥러닝 이해_2(예비군/2일차) (1) | 2023.08.29 |