
딥러닝 원리 이해
딥러닝과 인공 신경망
- 딥러닝: 사람의 뇌에서 이루어지는 원리를 이용하여 인공지능을 만드는 방식
- 인공 신경망(ANN, Artificial Neural Network): 신경망을 사람들이 인공적으로 만든 것
- 인공 신경망에서는 신경망의 최소 구성 단위인 뉴런이 다른 뉴런과 연결된 모습을 각각의 층,
즉 레이어(Layer)라는 개념을 사용하여 연결하고 있다. - 입력층: 데이터를 입력받는 층
- 출력층: 이 출력층에 어떠한 값이 전달되었ㄴ냐에 따라 인공지능의 예측 값이 결정됨
- 은닉층: 입력층에서 들어온 데이터가 여러 신호로 바뀌어서 출력층까지 전달됨
이때 연결된 여러 뉴런을 지날 때마다 신호 세기가 변경됨 - 심층 신경망(DNN, Deep Neural Network):
레이어가 한 층으로만 구성된 것이 아니라 깊은 층으로 구성된 인공 신경망 - 딥러닝(Deep Learning):
심층 신경망이 학습하는 과정
인공 신경망의 작동 모습
- 머신러닝으로 만든 인공지능이 남자와 여자를 추론하는 모습
- 인공지능이 지금까지 학습한 데이터와 동일한 형태의 데이터를 인공지능에 넣는다
- 이 데이터를 넣으면 검은색 박스를 지나며 결과를 보여준다
- 이때 이 검은색 박스를 어떻게 만드는지를 결정하는 것이 바로 머신러닝의 다양한 방법들이다
- 인공신경망 방식으로 만든 인공지능에서는 입력한 데이터가 여러 레이어를 지나가면서 특정한 신호로 전달됨
- 최종적으로 신호가 남자 쪽으로 가는지
여자 쪽으로 가는지를 판단하여
둘 중 어느 쪽으로 신호가 많이 가는지를 살펴본 후 신호가 많이 간 쪽 성별이라고 판단을 내림 - 인공 신경망 모델은 입력받은 데이터를 사용하여 추론한 결과를 보여준다
- 이때 신호를 정확한 출력값으로 보내는지, 그렇지 않은지가 바로 그 인공 신경망 모델의 성능을 결정
- 이때 인공 신경망 모델이 신호를 정확한 출력값으로 보내지 않는다면, 정확한 출력값으로 보낼 수 있도록 신호 세기를 조정하는 과정이 바로 인공 신경망의 학습 과정

인공 신경망의 신호 전달 원리
신호를 전달할 때 사용하는 가중치와 편향
- 신호를 받은 뉴련은 하나의 뉴런에서만 신호를 전달받은 것이 아닐 ㅏ여러 뉴런에서 신호를 전달받으며 인공신경망도 이와 비슷하다
- 이때 단순하게 신호를 전달해 주는 것이 아니라 신호 세시를 변경해서 전달
- 뒤쪽으로 전달되는 신호 세기는 앞쪽 뉴런에서 전달된 신호의 값에 가중치라는 값을 곱하고, 편향을 더해서 다음으로 전달
- 이와 같이 신호 세기는 가중치, 편향치에 따라 계속하여 변경됨


- 가중치는 심층 신경망의 각 뉴런과 뉴런을 연결하는 선에 있으며,
각 선에는 가중치라는 서로 다른 값들이 저장되어 있다 - 편향 값은 각 층에 하나의 값으로 존재
- 인공신경망이 학습한다는 의미는 이 가중치와 편향 값을 각 데이터에 맞게끔 정교하게 맞추어 감
들어오는 신호 세기를 조절하는 활성화 함수
뉴런이 전달하는 신호는 가중치와 편향을 거쳐온다.
서로 얽혀 있는 뉴런은 다음 뉴런에게 신호를 어떤 때에는 전달하고, 어떤 때에는 절달하지 않는다.

역치(actionpotiential)
특정한 전기적 신호가 어떤 값(역치) 이상 전달되었을 경우에는 다음 뉴런으로 신호를 전달하지만
어떤 값(역치)보다 작을 경우에는 전달하지 않는다

활성화(activation) 함수
여러 뉴련에서 들어오는 신호 세기를 특정한 값으로 바꾸기 위해 활성화 함수를 사용한다.
활성화 함수는 신호 세기를 조절하는데, 특히 레이어와 레이어 사이에 있어서 여러 뉴런에서 특정한 뉴런으로 들어가는 신호를 종합해서 하나의 값으로 바꿔 주는 역할을 함

시그모이드(Sigmoid) 함수
시그모이드 함수는 로지스틱 함수를 변형한 함수
- 로지스틱 함수: 어떤 생물들이 어떤 식으로 증가하는지 설명하는 모델
- 시그모이드 함수: 여러 뉴런에서 들옹는 신호 세기를 모아서 그 값이 0보다 클수록 1에 가까운 숫자로 바꿔 주고,
반대로 신호 세기가 0보다 작을수록 0에 가까운 숫자로 바꾸어 주는 특징을 가진 활성화 함수

하이퍼볼릭탄젠트(Tanh) 함수
- 값이 작은 신호를 -1에 가까운 숫자로 바꾸어서 내보낸다
- 시그모이드 함수를 사용하여 출력값이 0에 가까워지면 신경망이 잘 학습하지 못한다는 한계점이 있다
- 하지만 하이퍼볼릭탄젠트 함수는 0이 아닌 -1의 값을 출력하기 때문에 이 한계를 넘을 수 있다.

렐루(ReLU) 함수
- ‘고르게 한다’는 뜻의 Rectified와 ‘직선으로 이루어진’이라는 뜻의 Linear Unit이 결합
- 입력값이 0보다 작은 숫자일 때는 0으로 바꾸어서 내보내고,
입력값이 0보다 클 때는 입력받은 값이 출력되는 모습을 볼 수 있다.

- 렐루 함수는 최근 인공 신경망을 학습시킬때 활성화 함수로 주로 사용됨
- 입력값이 음수일 경우에 출력값이 0으로 같다는 단점이 있어서 이를 해결하기 위해 Leaky 렐루(Leaky ReLU) 함수 또는 새롭게 개발되어 사용되고 있다.
- Leaky 렐루 함수는 전달받은 신호 세기의 합이 음수일 경우에 0인 값을 출력하지 않고,
미세하게나마 차이가 나는 음수의 값을 전달한다.

소프트맥스 함수
- 최종 결괏값을 정규화하는데 사용하는 함수
- 인공 신경망의 출력층에 소프트맥스 함수를 사용하면 분류 문제를 해결할 수 있다
- 출력층에 따라서 분류의 개수 또한 달라진다.
- 소프트맥스 함수는 인공 신경망 모델에서 항상 사용되는 것이 아니라 분류 문제에서 사용되는 함수이다.

인공 신경망의 학습 원리
인공 신경망의 오차 구하기
특정한 값을 예측하는 문제
정답값과 예측 값의 차이를 구한 후 이 값들을 모두 더하면 인공지능의 오차값이 됨
이러한 오차값을 계산한 후 다음 번에는 이 오차값이 줄어들도록 인공지능을 잘 학습시킨다
이떄 오차가 크면 클수록 잘못 예측하는 인공지능이기 때문에, 여러번 학습시키면서 이 값을 줄여야 한다
기울기로 가중치 값을 변경하는 경사 강하법(Gradient Descent)
가중치에 따라 신호 세기가 바뀌고, 그에 따라 인공지능의 결괏값이 결정
인공지능의 학습 = 가중치를 적절하게 수행하는 과정

- 오차를 줄이려면 가장 오차가 작은 지점으로 가중치를 이동해야 함
- b 지점의 기울기가 가장 크며, a 지점으로 갈수록 기울기의 크기가 작아진다
- 우리가 목표로 하는 a 지점의 기울기는 가장 작은 0
- 경사 강하법(Gradient Descent):
기울기를 보고 기울기가 줄어드는 쪽으로 가중치 값을 이동
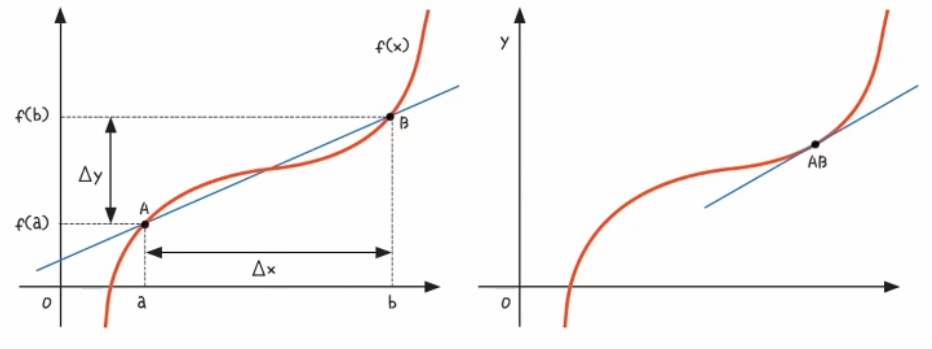
- 기울기가 가파를수록 다음 값의 변화가 크다,
기울기가 완만할수록 값의 변화가 작다 - 이러한 미분 개념을 사용하여 인공 신경망의 오차를 수정한다
- 경사 하강법의 핵슴은 미분이다
여러 가중치를 차례로 변경해 나가는 오차 역전파법(Back Propagation)
- 인공 신경망을 설계하면 가중치의 값이 한두 개가 아니라는 문제가 있다
- 오차 역전파법(Back Propagation):
오차를 끝에서부터 거꾸로 가면서 줄인다,
마지막부터 처음까지 되돌아가면서 경사 하강법을 사용하여 각각의 가중치 값을 수정

- 뒤로 가면서 가중치를 수정한 다음 다시 한번 데이터를 흘려보낸 수 결괏값을 살펴봄
- 그 결괏값이 정답값과 어떤 차이가 있는지 살펴본 후 다시 오차 역전파법을 사용하여 가중치를 수정
- 인공 신경망은 이 과정을 반복하여 오차를 0으로 줄여나감
- 이렇게 오차값을 계산하고 그 오차값에 따라 가중치를 점점 수정해나가는 모습이 바로 인공 신경망에서의 인공지능 학습 방법
텐서플로 플레이그라운드
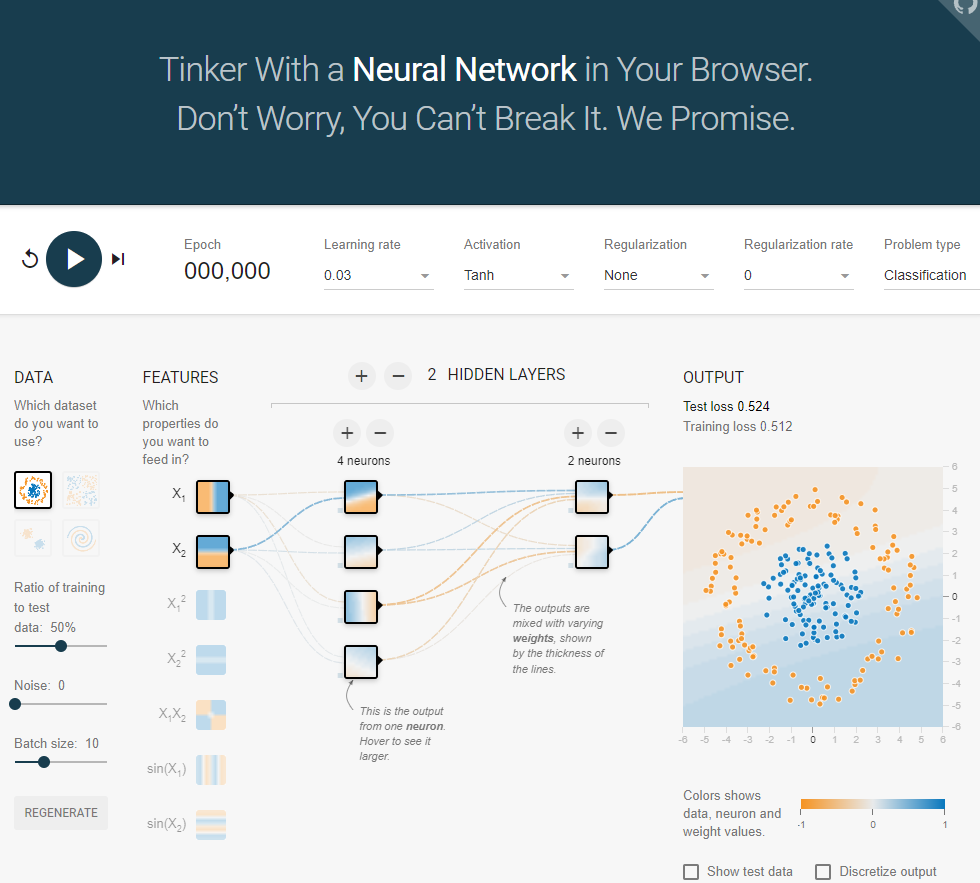
- 왼쪽 위에 에포크(Epoch)라고 적힌 숫자의 값이 늘어난다
- 에포크: 전체 데이터를 사용하여 인공 신경망이 학습한 횟수
- 에포크가 늘어나면서 변하는 모습 중 하나는 출력(OUTPUT)으로
그래프와 데이터 영역이 변한다. - 파란색 점이 있는 곳과 주황색 점이 있는 곳이 2개 영역으로 구분됨
- 그래프에서 볼 수 있듯이 오차 또는 0에 가까워지고 있다.

- 텐서플로 플레이그라운드의 데이터는 훈련 데이터(training data)와 검증 데이터(test data)로 구분되어 있다
- 화면에서 Show test data 버튼을 클릭하면 어떤 것이 검증 데이터인지 살펴볼 수 있다.
- 데이터를 훈련 데이터와 검증 데이터로 구분하는 이유는 신경망을 훈련하는 데 모든 데이터를 쓰지 않고 일부분만을 사용하기 위해서이다
- Test loss는 검증 데이터를 신경망에 넣었을 때 오차값
- Training loss는 훈련 데이터에 대한 오차값
- 학습이 점점 진행되며 각각의 오차값이 줄어드는 것을 볼 수 있다

HIDDEN LAYERS의 더하기, 빼기 버튼을 누르면 신경망 층의 개수를 수정할 수 있다

각 층에서 더하기, 빼기 버튼을 클릭하면 층의 뉴런의 수를 수정할 수 있다
뉴런의 수가 많을수록 더 정교한 학습이 가능하지만
무작정 층과 뉴련의 수를 늘릴 경우 필요없는 계산이 이루어질 수 있기 때문에 적정한 층과 뉴런의 수로 잘 정해야 한다.

- 화면 왼쪽의 DATA에서는 데이터의 입력 형태를 선택할 수 있다
- 기본적으로 X축과 Y축의 값을 입력
- 데이터의 형태
검증 데이터와 훈련 데이터의 비율(Ratio of training to test data)
노이즈(Noise)
배치 사이즈(Batch Size)
에포크(Epoch) 등의 값을 수정한 후 REGENERATE(재생성) 버튼을 클릭
- 입력값을 수정해 보면서 어떤 입력값이 가장 좋은 모델을 만드는 데 사용될 수 있는지 살펴볼 수 있다
- FEATURES에서 데이터의 모습과 비슷한 입력을 선택하니 금방 학습이 진행되는 것을 확인할 수 있다

- Learning rate: 딥러닝의 핵심 개념인 경사 하강법과 관련한 용어입니다.
딥러닝에서는 정답값과 예측 값의 오차를 최소화하는 방식으로 학습을 진행합니다. 이때 오차값을 최소화하기 위해 각 뉴런을 연결하는 가중치 값을 수정해 나가는데 한 번 수정할 때 얼마만큼 수정할지를 Learning rate 값으로 결정 - Activation: 활성화 함수를 의미합니다
텐서플로 플레이그라운드에서는 ReLU, tanh, Sigmoid, Linear 함수를 사용할 수 있다 - Regularization: 정규화를 의미합니다
정규화의 목적은 과적합(overfitting)을 줄이는 것입니다. 과적합은 모델이 학습된 데이터에는 잘 작동하지만 이전에 보지 못한 데이터에는 예측이 좋지 않은 상태를 의미 - Regularization rate: 정규화할 때 어느 정도로 값을 수정할지 정해줄 때 사용하는 값
- Problem type: 텐서플로 플레이그라운드에서는 문제를 분류(Classification)와 회귀(Regression)로 나눕니다.
분류 문제는 데이터를 주황색과 파란색의 데이터로 분류하도록 데이터를 학습시키는 것을 의미하고, 회귀 문제는 연속된 데이터의 값을 예측하도록 인공지능을 학습시키는 것을 의미한다.
본 후기는 정보통신산업진흥원(NIPA)에서 주관하는 <AI 서비스완성! AI+웹개발 취업캠프 - 프론트엔드&백엔드> 과정 학습/프로젝트/과제 기록으로 작성되었습니다.
'코딩캠프 > AI 웹개발 취업캠프' 카테고리의 다른 글
| [AI 웹개발 취업캠프] 32Day - 파이썬과 코랩(예비군/3일차) (0) | 2023.08.30 |
|---|---|
| [AI 웹개발 취업캠프] 31Day - 딥러닝 이해_2(예비군/2일차) (1) | 2023.08.29 |
| [AI 웹개발 취업캠프] 인공지능(AI) 능력시험 AICE Basic 대비 올인원 패키지 (1) (2) | 2023.08.27 |
| [AI 웹개발 취업캠프] 23.08.25 과제 (3) | 2023.08.25 |
| [AI 웹개발 취업캠프] 29Day - 머신러닝, 딥러닝, 빅데이터 (0) | 2023.08.25 |